时序数据库连载系列:Berkeley 的黑科技 BTrDB
来源:焦先 发布时间:2019-02-23 16:56:33 阅读量:1955
本文是对面向 IoT 领域的开源时序数据库 BTrDB 内部实现细节的研究和介绍。
1. 场景介绍
BTrDB 论文中介绍了一个实际的项目,能很好解释清楚 BTrDB 的设计初衷和适用场景:
在一个电网中大量部署了某类传感器,每个传感器会产生 12 条时间线,每条时间线频率为 120Hz(即每秒 120 个点),时间精度为 100ns;由于各种原因,传感器数据传输经常性出现延迟、(时间)乱序等。BTrDB 在该场景下单机能支撑 1000 个类似的传感器,写入速率约 1.44M points/s。
该项目有这样几个特点:
1. 时间线在很长时间内有一定的不变性,其生命周期跟(IoT)设备周期一致
2. 数据频率很高(120 Hz)且固定
3. 数据的时间分辨率很高(100ns级别),一般如Druid,TimescaleDB 时间精度最多做到 ms 级别
4. 数据传输经常性出现乱序
5. 时间线数量有限
BTrDB 为了适应上述场景,设计并提出了 "time-partitioning version-annotated copy-on-write tree" 的数据结构,为每一条时间线构建了一棵树(可以参考B+Tree),数据在该树中按照时间戳排序,叶子节点有序得存放某个时间段内的时序数据。
可以想见,这棵树的生命周期跟设备的生命周期直接挂钩,因此随着时间的发展,这棵树即使只包含一条时间线,也会占用很可观的存储空间(约 10M points/day);另外由于是基于树结构,并且引入了版本(version-annotated) 的概念,BTrDB 可以很好的支持乱序数据和任意精度的时序数据。
由于数据结构不同于以往时序数据库基于LSM-Tree的变种,因此 BTrDB 还提供了一套新的时序数据查询接口,方便在 BTrDB 上层构建各种算法和应用。
2. 数据结构
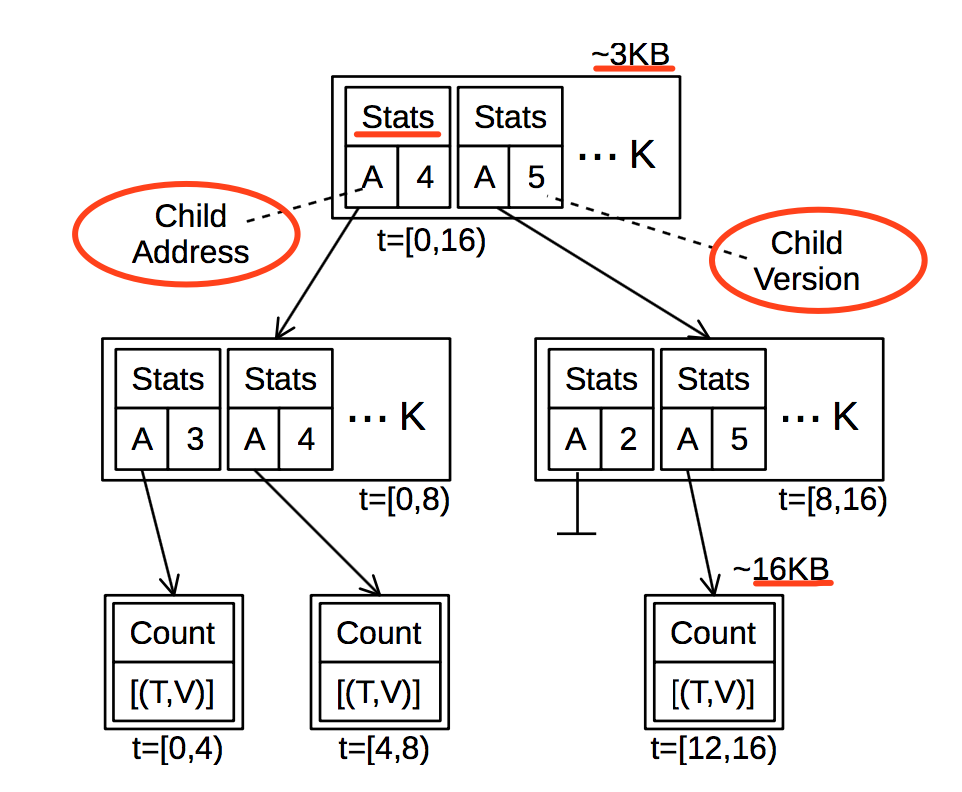
2.1 version-annotated & CoW 特性
在数据写入时,BTrDB 会先修改在内存中的数据块(新建或者使用 CoW 机制修改已有块),当数据达到一定阈值时再写回底层块存储;由于 CoW 机制,并且底层块存储(默认使用Ceph)无法覆盖更新,因此只能创建一个新版本的数据块。
2.2. 叶子节点
对于 IoT 设备发来的数据,由于频率固定,这些叶子节点占用空间大小基本一致。
叶子节点还未持久化到底层存储时,在内存中通过数组的方式分别存放时间戳和(双精度浮点)值;在序列化到底层存储时,会通过delta-delta的方式压缩时间戳和值;在序列化双精度浮点数值之前,会将浮点数据数拆分为尾数和指数两部分,并分别进行delta-delta压缩。
2.3. 中间节点:
中间节点被划分为多个 bucket,每个 bucket 中存放着指向子节点的链接(带版本号)以及子节点的统计数据:
子节点的时间范围
聚合数据,如 sum, max, min,count 等
子节点连接地址和版本号
在处理查询时,如果中间节点的时间精度满足查询需求,查询操作就不再读取下层子节点了,这样就很自然的实现了将精度功能;这种实现方式,能够很好的处理乱序、重复数据以及删除操作,并且与其他现有的实现相比,能够很好的保证数据的一致性。
2.4. 插入时树的分裂
一棵新的树(对应一条新的时间线)只有一个根节点,在 BTrDB 的实现中,根节点时间跨度约为146.23年,这样每个 bucket 的时间跨度为 146.23/64 ~= 2.28 (年),根据默认配置,1970年在根节点的第16个 bucket。
可见,根节点在创建时就已经限制了数据的时间范围,后续数据的插入是自顶向下逐层分裂的,当数据因为丢失等原因造成时间线不完整时,部分节点的深度可能会不一样,因此并不是一颗严格的平衡树。数据插入过程如下:
数据插入操作从根节点开始;
如果当前节点是中间节点,则遍历每个数据,为每个数据找到对应的 bucket;
如果对应的 bucket 不存在,则创建新的 bucket 和与该 bucket 关联的子节点:
如果当前 bucket 待插入的点个数超过叶子节点最大点数(默认1024),则直接创建中间子节点;
否则,创建叶子节点;
将数据插入到与所属 bucket 关联的子节点中;
如果当前节点是叶子节点,节点中数据个数和待插入数据个数总合超过 1024 个点,则分裂当前节点创建出新的中间节点,将数据插入新的中间节点;否则将待插入数据和当前节点已有数据合并,并按照时间戳排序;
当前节点插入成功后,自底向上更新父节点的统计信息;
从上面过程可以看到,节点在插入时在两个地方可能出现分裂。一个是从根节点开始,自顶向下分裂;另一个是从叶子节点开始,向上分裂。
虽然这棵树并不是一颗平衡树,但是对于 IoT 类项目,设备的时间线生命周期、数据采集频率很稳定,在绝大多数场景下,节点中数据都是均衡分布的。
2.5 节点占用的内存空间
在默认实现中,叶子节点中最多存储1024个数据点;中间节点中最多存储64个子节点指针,因此:
对于还未持久化的叶子节点,占用的内存空间为:
1024*2*8 = 16K(见 2.2.1)对于还未持久化的中间节点,占用的内存为:
64*6*8 + 64*2*8 = 4K(见 2.2.2)
3. 数据存储相关
3.1 写 WAL
在数据插入时,会先将数据写入到 WAL(Write Ahead Log) 中;
每次写 WAL 都会返回一个check point,代表数据在WAL中的写入位置;
WAL 写入成功后,原始数据和 check point 会被写入时间线的缓冲区;
时间线的缓冲与时间线一一对应,最大容纳32768个数据点;
当缓冲区满时,数据会被插入到树结构中,并将该缓冲区对应的 check points 在 WAL 中标记为删除状态;
在 WAL 的 replay 过程中会根据已被删除的 check points 过滤原始数据。
下面的示意图展示了WAL中 check points 与时间序列缓冲区的关联关系,在缓冲区清空后,BTrDB 会将已经删除的 check points 写入到当前 WAL 对应的块文件的元信息(block attributes)中:
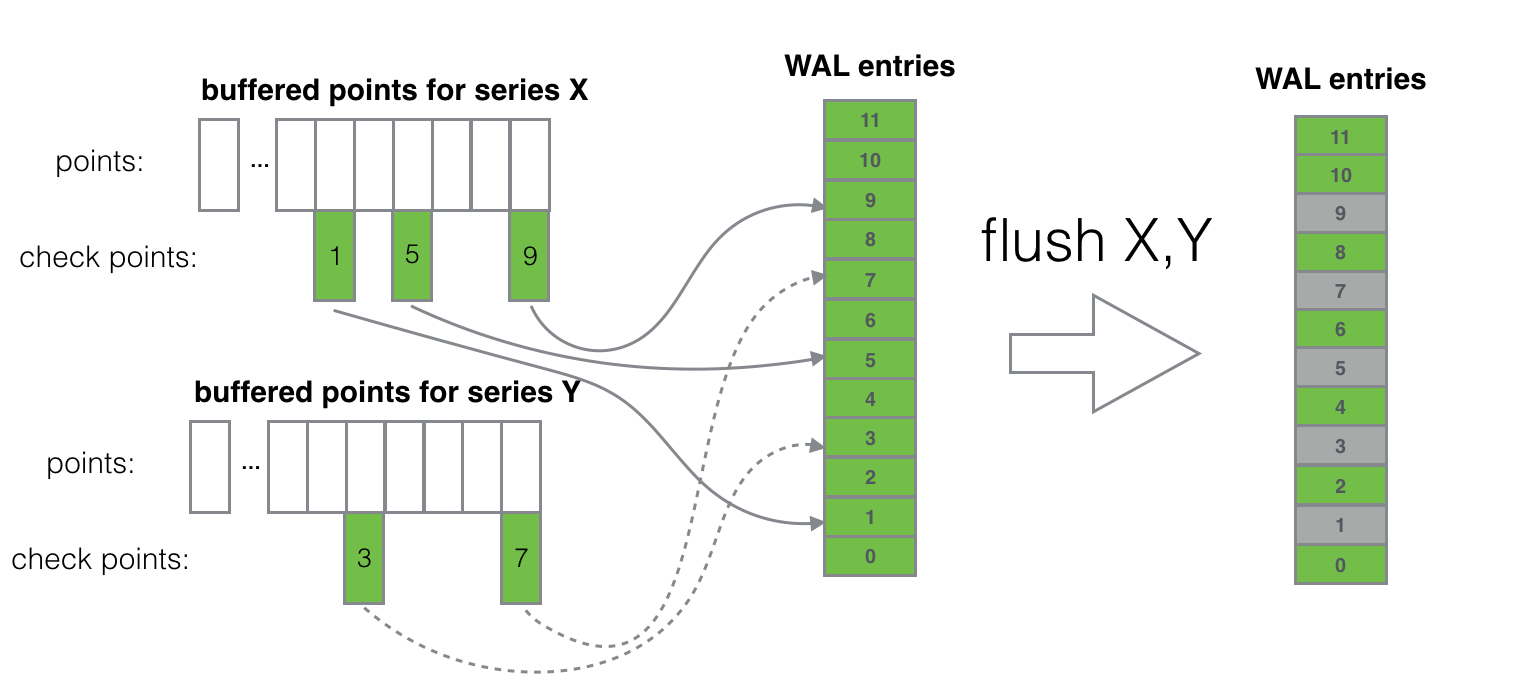
当一个 WAL 块文件中所有的 check points 都标记为已删除时,该文件就可以从 Ceph 中删除了。当前 WAL 文件大小超过16M时就会创建新的块文件,在理想情况下,块文件都能被及时删除;但是如果某些时间线出现异常,向前文提到的,其缓冲区在 8 小时后才能被回收,那么负责记录这些时间线的 WAL 文件也就只能在8小时后被回收。
这些滞留的 WAL 文件大小只有16M,数量与出现异常的 IoT 设备数量成线性关系,因此需要更多 IoT 设备运行统计数据才能统计其影响。
3.2 写 Block
BTrDB 的树结构在持久化后会产生两类数据,一个称为 superblock,记录了当前树的最新版本、更新时间、根节点位置等基本信息;另外一个称为 segment,统一包含了树的叶子节点和中间节点的数据。
superblock 是带版本的,每个版本的 superblock 只占用16Byte,格式为:
{root: 根节点位置,8Byte, timestamp: 修改时间,8Byte}superblock 在 Ceph 中的寻址方式为:
块存储 id = uuid.toString() + (version >> 20)
块存储中的 offset = (version & 0xFFFFF)*16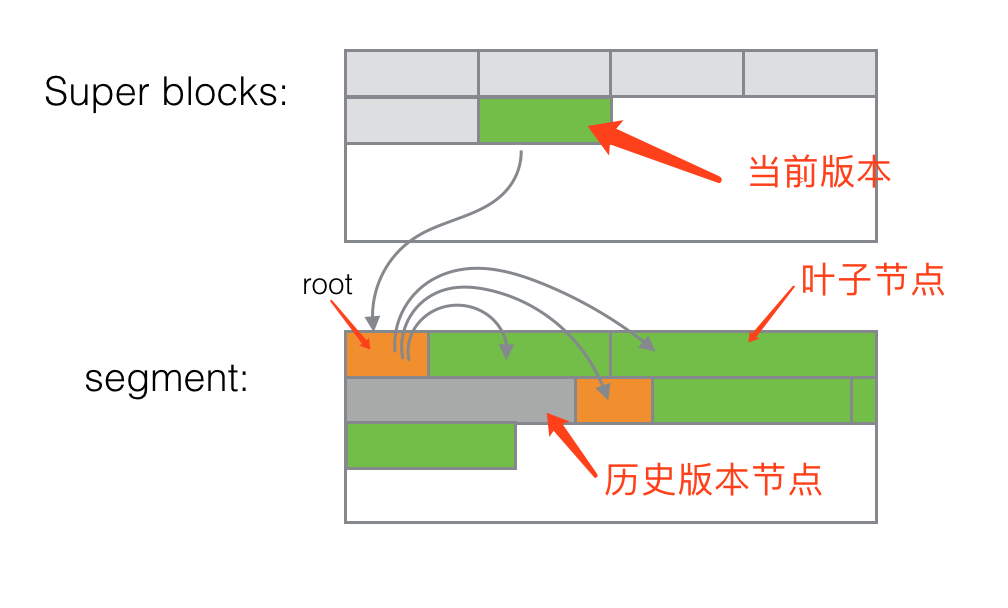
在 BTrDB 中持久化树结构时叶子节点和中间节点会一并序列化到 segment 中,每个节点的寻址编码方式为:
块存储的 id = uuid.toString() + (address >> 24)
节点在块存储中的偏移量 = (address & 0xFFFFFF)可以看到, WAL 文件, superblock 块文件以及 segment 块文件大小都是 16M。另外,BTrDB 中没有 compaction,也没有对过期版本数据的清理,只有上文中介绍的对 WAL 的处理,写入放大会很明显。
新的查询语义
这里只是罗列、简单介绍下 BTrDB 提供的新的查询语义,这些查询语义的提出与 BTrDB 的数据结构有很大关系,或者是为了利用树结构某些特性,或者是为了规避树结构一些不足:
GetRange(UUID, StartTime, EndTime, Version) → (Version, [(Time, Value)]) 查询时间线在某个时间范围内的详细(原始)数据;
GetLatestVersion(UUID) → Version 查询时间线最新版本;
GetStatisticalRange(UUID, StartTime, EndTime, Version, Resolution) → (Version, [(Time, Min, Mean, Max, Count)]) 获取给定时间范围内,满足一定时间精度的,大于等于给定版本的时间线的聚合数据;
GetNearestValue(UUID, Time, Version, Direction) → (Version, (Time, Value)) 向前、向后获取下一个点;
ComputeDiff(UUID, FromVersion, ToVersion, Resolution) → [(StartTime, EndTime)] 在满足给定时间精度条件下,获取两个版本号范围内,所有更新节点的起止时间;适合做增量计算。
上面接口中的时间分辨率参数(Resolution),对于接口的性能有很大影响。前文提到根节点的时间分辨率是2.2年,从树的根节点到底层节点,节点中数据的时间分辨率越来越高;在查询时,低分辨率数据聚合程度高,扫面的数据块少;高分辨率的数据聚合程度低,但是需要扫面的数据块很多。
总结
BTrDB 中数据结构是针对单条时间线构建的,并且针对 IoT 设备数据稳定的特点,构建了一棵树来存储时序数据;树结构解决了传统 TSDB 在乱序插入、删除、预降精度等方面面临的问题。

 13450931319
13450931319 微信登录
微信登录
 QQ登录
QQ登录
 微博登录
微博登录


 售前咨询
售前咨询
